
Alpha–beta pruning facts for kids
| Class | Search algorithm |
|---|---|
| Worst-case performance | 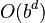 |
| Best-case performance | 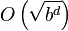 |
Alpha–beta pruning is a clever trick used in search algorithms. It helps computers play two-player games like Chess, Tic-tac-toe, or Connect 4 much better. Imagine a computer trying to figure out its next move in a game. It looks at all possible moves and what might happen after them, like building a huge "game tree" of possibilities.
Alpha–beta pruning helps the computer by letting it ignore parts of this game tree that it knows won't lead to a good outcome. It's like saying, "If this move leads to a guaranteed loss, I don't need to explore all the ways I could lose from here; I'll just pick a different starting move." This makes the computer think faster and look deeper into the game.
Contents
How Alpha–Beta Pruning Started
The idea behind alpha–beta pruning has been thought of by many people over time. Allen Newell and Herbert A. Simon wrote about a similar idea in 1958. Arthur Samuel used an early version for a checkers game simulation.
Other computer scientists like John McCarthy and his students at MIT, including Alan Kotok, also came up with similar concepts. Alexander Brudno published his findings on the algorithm in 1963. Later, Donald Knuth and Ronald W. Moore made the algorithm even better in 1975.
The Main Idea Behind It
Think of a game like chess or checkers. You can draw out all the possible moves and counter-moves, creating a "game tree." Each point in this tree is a possible situation in the game. The computer wants to find the best path through this tree to win.
Alpha–beta pruning works by keeping track of two important numbers:
- Alpha (α): This is the best score the player whose turn it is (the "maximizing player") can guarantee for themselves so far.
- Beta (β): This is the best score the opponent (the "minimizing player") can guarantee for themselves so far.
At the start, alpha is a very low number (like negative infinity), and beta is a very high number (like positive infinity). This means both players start with their worst possible score.
The magic happens when the opponent's guaranteed best score (beta) becomes less than the current player's guaranteed best score (alpha). If `beta < alpha`, it means the current path is already worse than a path we've found before. So, the computer can stop looking down this path because it knows it won't be the best choice. This is called "pruning" the tree.
For example, imagine you're playing chess. You're looking at a move, let's call it "Move B." You realize that if you make Move B, your opponent can force a checkmate in just two moves. You've already found another move, "Move A," that doesn't lead to a forced loss. So, you don't need to explore all the other ways you could lose after Move B. You just know Move B is bad, and you can stop thinking about it.
Why It's Better Than Simple Minimax

The biggest benefit of alpha–beta pruning is that it cuts down the number of possibilities the computer has to check. This means the computer can look much deeper into the game in the same amount of time. It's like having a superpower that lets you see twice as far into the future of the game!
For example, a chess program might need to check over a million possible game endings with a simple search. But with alpha–beta pruning, it might only need to check about 2,000! That's a huge difference and makes the computer much faster and smarter.
The order in which the computer checks moves also matters a lot. If it checks the best moves first, alpha–beta pruning works even better. Chess programs often use tricks to guess which moves are likely to be good, helping the algorithm work its magic more efficiently.
Making It Even Smarter
Computers can use other smart tricks, called "heuristics," to make alpha–beta pruning even faster without losing accuracy. These tricks help the computer guess which parts of the game tree are most likely to lead to a "pruning" opportunity.
- Move Ordering: For example, in chess, moves that capture an opponent's piece might be checked first because they often lead to important changes in the game.
- Killer Heuristic: This trick remembers moves that caused a "cutoff" (a pruning) at the same level of the game tree before. It tries those moves first next time.
- Aspiration Search: This is like giving the computer a narrow "window" of scores to look for. If the best score falls outside this window, the computer knows it needs to search again with a wider window.
These improvements help the computer make decisions even faster, especially in complex games.
Other Ways Computers Search
While alpha–beta pruning is very popular, there are other ways computers can search for the best moves.
- Iterative Deepening: This method involves searching the game tree to a shallow depth first, then a bit deeper, and then even deeper. This way, if the computer runs out of time, it can still give a reasonably good move based on its shallower searches. It also helps alpha–beta pruning by giving it hints about which moves are likely to be good.
- Best-First Search: Some algorithms, like SSS*, try to explore the most promising paths first. This can sometimes be faster, but it might use a lot more computer memory.
See also
 In Spanish: Poda alfa-beta para niños
In Spanish: Poda alfa-beta para niños
- Minimax
- Expectiminimax
- Negamax
- Pruning (algorithm)
- Branch and bound
- Combinatorial optimization
- Principal variation search
- Transposition table
Images for kids
-
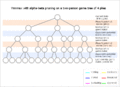
An animated example showing how Alpha–beta pruning works by avoiding unnecessary calculations.

