
FLOPS facts for kids
FLOPS (which stands for FLoating-point Operations Per Second) is a way to measure how fast a computer can do math. It's especially useful for tasks that need lots of complex calculations, like scientific research or creating realistic graphics. Think of it as how many math problems a computer can solve in one second!
Computers use floating-point numbers for very large or very small numbers, similar to how we use scientific notation (like 1.2 x 10^23). This helps computers handle a huge range of values accurately.
| Name | Unit | Value |
|---|---|---|
| kiloFLOPS | kFLOPS | 1,000 |
| megaFLOPS | MFLOPS | 1,000,000 |
| gigaFLOPS | GFLOPS | 1,000,000,000 |
| teraFLOPS | TFLOPS | 1,000,000,000,000 |
| petaFLOPS | PFLOPS | 1,000,000,000,000,000 |
| exaFLOPS | EFLOPS | 1,000,000,000,000,000,000 |
| zettaFLOPS | ZFLOPS | 1,000,000,000,000,000,000,000 |
| yottaFLOPS | YFLOPS | 1,000,000,000,000,000,000,000,000 |
| ronnaFLOPS | RFLOPS | 1,000,000,000,000,000,000,000,000,000 |
| quettaFLOPS | QFLOPS | 1,000,000,000,000,000,000,000,000,000,000 |
,_OWID.svg)
Contents
Why FLOPS Matters for Computer Speed
FLOPS helps us understand how powerful a computer is for tasks that need lots of math. This is different from MIPS (Million Instructions Per Second), which measures how fast a computer handles simpler tasks like moving data or checking if two values are the same.
For things like playing advanced video games, creating movie special effects, or running weather simulations, FLOPS is a much better way to compare computers. The more FLOPS a computer has, the faster it can do these complex jobs.
A scientist named Frank H. McMahon created the terms FLOPS and MFLOPS (megaFLOPS) to compare the supercomputers of his time. He wanted a way to measure how good they were at doing actual math, not just how many simple instructions they could follow.
How FLOPS is Calculated
You can figure out a computer's FLOPS using a math formula. For a computer with one main processor (CPU), it looks like this:
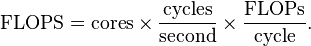
- Cores: These are like mini-brains inside your computer's main processor. More cores mean more math can be done at once.
- Cycles per second: This is how fast the processor works, measured in hertz (like gigahertz). A higher number means it works faster.
- FLOPS per cycle: This tells you how many math operations each core can do in one cycle.
FLOPS can also be measured with different levels of accuracy, called "precision." For example, the list of the world's fastest supercomputers (TOP500) ranks them by how many 64-bit operations they can do per second (called FP64). There are also measures for 32-bit (FP32) and 16-bit (FP16) operations.
Amazing Performance Records
Over the years, computers have become incredibly fast, breaking new FLOPS records!
Single Computer Records
- In 1997, Intel's ASCI Red was the first computer to reach one teraFLOPS (a trillion operations per second).
- In 2006, Japan's MDGRAPE-3 computer reached one petaFLOPS (a thousand trillion operations per second). It was built for special tasks like simulating how molecules move.
- By 2007, IBM's Blue Gene/L supercomputer could do almost 600 teraFLOPS. Later, the Blue Gene/P was designed to go beyond one petaFLOPS.
- In 2008, the IBM Roadrunner became the first supercomputer to reach one petaFLOPS. It was located at Los Alamos National Laboratory in New Mexico.
- Also in 2008, some graphics cards (GPUs) like the AMD ATI Radeon HD 4800 series were the first to reach one teraFLOPS.
- In 2009, the Cray Jaguar supercomputer hit 1.75 petaFLOPS, becoming the fastest in the world at the time.
- In 2010, China's Tianhe-1 supercomputer reached 2.5 petaFLOPS.
- In 2011, Japan's K computer achieved an amazing 10.51 petaFLOPS. It had over 88,000 processors!
- In 2012, IBM's Sequoia supercomputer reached 16 petaFLOPS.
- Later in 2012, Titan from Cray Inc. became the fastest at 17.59 petaFLOPS.
- In 2013, China's Tianhe-2 took the top spot with 33.86 petaFLOPS.
- In 2016, China's Sunway TaihuLight was ranked the world's fastest with 93 petaFLOPS.
- In 2019, Summit, an IBM-built supercomputer, reached 148.6 petaFLOPS.
Distributed Computing Records
Sometimes, many personal computers work together over the internet to solve huge problems. This is called distributed computing.
- As of 2020, the Folding@home network had over 2.3 exaFLOPS (a million trillion operations per second) of total power. It was the first to break 1 exaFLOPS! This massive power comes from many people sharing their computer's power.
- Other projects like BOINC, SETI@home, Einstein@Home, MilkyWay@home, and GIMPS also use distributed computing to achieve incredible FLOPS numbers.
The Cost of Computing Power
The cost of getting more computing power has dropped a lot over time. What used to cost millions of dollars now costs just a few cents per GFLOPS!
| Date | Approximate Cost per GFLOPS (in US Dollars) | What was the cheapest way to get this power? | Notes |
|---|---|---|---|
| 1945 | $130 trillion | ENIAC | The very first electronic digital computer. |
| 1961 | $20 billion | IBM 7030 Stretch | A second-generation computer using transistors. |
| 1984 | $20,000,000 | Cray X-MP/48 | A third-generation computer using integrated circuits. |
| 1997 | $30,000 | Beowulf clusters | Clusters of many smaller computers working together. |
| April 2000 | $1,000 | Bunyip Beowulf cluster | One of the first to get under $1 per MFLOPS. |
| August 2007 | $50 | Microwulf | A "personal" Beowulf cluster you could build for about $1256. |
| March 2011 | $1.80 | HPU4Science | A cluster built with regular "gamer" computer parts. |
| August 2012 | $0.75 | Quad AMD Radeon 7970 System | A desktop computer with multiple graphics cards. |
| June 2013 | $0.22 | Sony PlayStation 4 | A gaming console offering a lot of power for its price. |
| September 2022 | $0.02 | RTX 4090 | A powerful graphics card from Nvidia. |
| May 2023 | $0.01 | Radeon RX 7600 | A graphics card from AMD, showing how cheap computing power has become. |
See also
 In Spanish: Operaciones de coma flotante por segundo para niños
In Spanish: Operaciones de coma flotante por segundo para niños
- Computer performance by orders of magnitude
- Moore's law
- Performance per watt#FLOPS per watt
- Exascale computing
- TOP500
