
ASCII facts for kids

ASCII (say "az-kee") is a special code that computers use to understand text. It helps computers read and show letters, numbers, and symbols from the English alphabet. ASCII stands for American Standard Code for Information Interchange. It was created in the 1960s, building on older codes used for sending messages by telegraph.
ASCII has codes for 128 different characters. Most of these are characters you can print, like "a", "B", "1", and "?". There are also "control characters" that you cannot print. Instead, they tell the computer how to handle text, like starting a new line. Many of these control characters are not used much anymore. ASCII itself does not control text formatting, like making words bold or italic.
Sometimes, when people talk about a file being in "ASCII," they mean it is in plain text. This means it has no special formatting.
ASCII usually uses 7 binary digits (bits) to represent each character. For example, the letter "A" is 1000001 in binary. This is 65 in our normal counting system. "B" is 1000010, and so on. Sometimes, an eighth bit was added to each byte. This extra bit helped check for errors when sending data, especially when connections were not very good.
What is Extended ASCII?
ASCII was mostly made for English. It does not include special marks called diacritics. These are marks added to letters, like the dots over the "u" in "ü" (used in German) or the tilde over the "n" in "ñ" (used in Spanish). Because of this, ASCII does not work well for most other languages.
To fix this, some computer systems started using 8 bits (a full byte) instead of 7 bits for each character. This is called extended ASCII. Using 8 bits allows for 256 different characters. The first 128 characters are the same as standard ASCII. The extra 128 characters are often used for letters with accents, like É, È, Î, and Ü.
Extended ASCII helps with languages based on the Latin alphabet. However, not all extended ASCII systems are the same. Other alphabets, like Greek or Cyrillic, need different sets of characters. Languages like Chinese use thousands of characters, so extended ASCII still does not work for them. This is why unicode was created. Unicode is a much larger system that aims to have one common code for all languages.
Standard ASCII is still used a lot today. You can find it in computer software and HTML files, which are used to build web pages. Until 2010, it was also the standard for URLs (website addresses). Many websites only accept ASCII text when you type into a text box. If you try to use special formatting, it might not show up correctly.
Images for kids
-
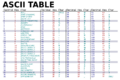
A wider view of the ASCII character table.

See also
 In Spanish: ASCII para niños
In Spanish: ASCII para niños
