
Compiler facts for kids
In computing, a compiler is a special computer program. It takes computer code written in one programming language (called the source language) and changes it into another language (the target language). Think of it like a translator for computers!
Compilers are mostly used to turn code from a high-level programming language (like Python or Java) into a lower level language (like machine code). This machine code is what the computer's CPU can understand and run directly. The goal is to create a program that can be used.
There are different kinds of compilers. A cross-compiler makes code for a different type of computer or operating system than the one it's running on. A bootstrap compiler is a temporary compiler. It helps build a better, more permanent compiler for a language.
Other related programs include decompilers, which translate low-level code back to higher-level code. Source-to-source compilers (or transpilers) translate between two high-level languages. Compiler-compilers are tools that help create other compilers.
A compiler usually works in several steps, called phases. These include preprocessing, lexical analysis, parsing, semantic analysis, and code generation. Compilers are designed carefully to make sure they work correctly. This is because mistakes in a compiler can be very hard to fix later.
Compilers are not the only programs that process code. An interpreter also translates code, but it runs the instructions right away. It doesn't create a separate executable program first. Some programming languages can use both compilers and interpreters.
Contents
How Compilers Started

The idea of modern computers began during World War II. Early computers understood only ones and zeros. So, programmers had to write code in very basic binary languages. In the late 1940s, assembly languages were created. These were a bit easier to use than binary.
Early computers had very little memory. This made designing the first compilers quite hard. Compiling a program had to be broken into many small steps. Each step was done by a different small program. As computers got more powerful, compilers could be designed to be more complete.
Programmers found it much easier to use high-level languages. These languages are defined by their specific rules, called syntax and semantics. These rules include:
- Alphabet: A set of symbols used in the language.
- String: A sequence of these symbols.
- Language: A collection of strings that follow the rules.
The rules for how sentences in a language are built are called a grammar. Backus–Naur form (BNF) is a way to describe these grammar rules. It was used for the Algol 60 language.
Between 1942 and 1945, Konrad Zuse designed the first programming language for computers, called Plankalkül. He also imagined a device to automatically translate programs into machine-readable form.
Between 1949 and 1951, Heinz Rutishauser suggested a high-level language called Superplan. His ideas helped shape later compiler designs.
Many important high-level languages were created early on:
- FORTRAN (Formula Translation) was for science and engineering. It was one of the first high-level languages to be fully used.
- COBOL (Common Business-Oriented Language) became popular for business programs.
- LISP (List Processor) was for working with symbols and lists.
Compilers became necessary to turn these high-level programs into low-level code for computers. A compiler could be seen as having a "front end" to analyze the source code and a "back end" to create the target code.
Here are some important moments in compiler history:
- May 1952: Grace Hopper's team created the compiler for the A-0 System language. They even came up with the word compiler.
- 1952: An Autocode compiler was made by Alick Glennie for the Manchester Mark I computer. Some see this as the first compiled language.
- 1954–1957: A team led by John Backus at IBM developed FORTRAN. In 1957, they finished a FORTRAN compiler. This is often seen as the first truly complete compiler.
- 1959: The development of COBOL began. By the early 1960s, COBOL could be compiled on many different computers.
- 1958–1960: Algol 58 and ALGOL 60 were created. ALGOL 60 was the first language to allow functions inside other functions. It also allowed recursion, where a function calls itself.
- 1958–1962: John McCarthy designed LISP. It was very useful for artificial intelligence research.
In the 1960s and 1970s, people started writing operating systems and other software in high-level languages. This was a big change from using assembly language. Languages like BCPL, BLISS, B, and C were developed for this purpose.
BCPL was designed in 1966 by Martin Richards. It was first used to write compilers. BCPL influenced the design of the B and C languages.
BLISS was made for a DEC PDP-10 computer. The team that made it later created the BLISS-11 compiler in 1970.
The Multics operating system was written in PL/I. This language was designed by IBM to meet many programming needs. An early PL/I compiler helped the Multics project.
Bell Labs developed the B language based on BCPL. Dennis Ritchie and Ken Thompson wrote it. Ritchie created a compiler for B and wrote the Unics operating system in B. Unics later became Unix.
Bell Labs then started developing C, building on B and BCPL. By 1973, the C language was mostly finished. The Unix operating system was then rewritten in C.
Object-oriented programming (OOP) became important for making and maintaining applications. C++ was developed at Bell Labs. It combined C's system programming power with OOP ideas from languages like Simula. C++ compilers became very popular.
As programming languages grew more complex, compilers also became more advanced. The GNU Compiler Collection (GCC) is a well-known example. It can compile many different languages for many different computer systems.
Today, compilers are often part of larger development tools. These are called integrated development environments (IDEs). Modern scripting languages like PHP, Python, Ruby, and Lua also have both interpreter and compiler support.
How Compilers Are Built
A compiler takes a high-level program and changes it into a low-level program. Compiler design can be a complete solution or just a part that works with other tools.
In the past, compilers were often one big program. But as languages became more complex, compilers were split into several parts, or "phases." This makes them easier to design and build.
One-Pass vs. Multi-Pass Compilers
Early computers had limited memory. So, compilers had to work in several steps, or "passes." Each pass would do a small part of the translation.
A single-pass compiler does all its work in one go. This makes it simpler to write and generally faster. Some early languages, like Pascal, were designed to be compiled in a single pass.
However, some language features need more than one pass. For example, if a definition on line 20 affects code on line 10, the compiler needs to read the whole program first.
Multi-pass compilers can do more advanced optimizations. These optimizations make the final code run faster or use less memory. It's hard to count exactly how many passes an optimizing compiler makes.
Splitting a compiler into smaller programs also helps researchers prove that the compiler works correctly.
Three Main Stages of a Compiler

Most compilers have three main stages: a front end, a middle end, and a back end.
- The front end reads the input code. It checks for correct syntax (grammar) and semantics (meaning) for the specific language. If there are errors, it gives messages. The front end turns the input program into an intermediate representation (IR). This IR is a simpler version of the program.
* Lexical analysis (or lexing) breaks the code into small pieces called tokens. Think of tokens as words in the computer's language. * Syntax analysis (or parsing) checks the order of these tokens. It builds a parse tree, which shows the program's structure. * Semantic analysis adds meaning to the parse tree. It checks for things like type errors (e.g., trying to add text to a number).
- The middle end works on the IR. It performs optimizations that don't depend on the specific computer it's targeting. This means the same optimizations can be used for different languages and different computer types. Examples include removing useless code or finding constant values.
- The back end takes the optimized IR. It performs more optimizations that are specific to the target computer's architecture. Then, it creates the final machine code. This code is specialized for a particular processor and operating system.
This three-stage design is very useful. It allows different front ends (for different languages) to work with different back ends (for different CPUs). They all share the optimizations done in the middle end. The GNU Compiler Collection (GCC) and Clang are examples of compilers that use this approach.
Front End Details
The front end's job is to analyze the source code. It builds an internal representation of the program. It also manages a symbol table. This table keeps track of all the names (like variables and functions) in the code and their details.
The front end is often broken into these phases:
- Preprocessing: This handles things like macros (shortcodes that expand into longer code) and conditional compilation (including or excluding parts of code based on conditions).
- Lexical analysis (or tokenization): This breaks the source code text into a sequence of lexical tokens. For example, it might identify "if" as a keyword, "total" as an identifier, and "10" as a number.
- Syntax analysis (or parsing): This takes the tokens and checks their order. It builds a parse tree (or syntax tree) based on the language's grammar rules.
- Semantic analysis: This adds more meaning to the parse tree. It checks for errors like using a variable before it's given a value.
Middle End Details
The middle end, also called the optimizer, makes the program run better. It works on the intermediate representation. The optimizations here are general and don't depend on the specific computer.
The main parts of the middle end are:
- Analysis: This gathers information about the program. It helps understand how data flows and how different parts of the code depend on each other.
- Optimization: The intermediate code is changed to be faster or smaller. Examples include making functions run directly in the code (inline expansion) or removing code that is never used.
These analysis and optimization steps work closely together. The more analysis a compiler does, the better it can optimize the code. However, more analysis takes more time and memory during compilation. So, some compilers let users choose how much optimization they want.
Back End Details
The back end focuses on making the code work best for the specific computer.
- Machine dependent optimizations: These are optimizations that use the special features of the target CPU. For example, rewriting short sequences of instructions into more efficient ones.
- Code generation: This is where the intermediate code is turned into the final machine language. It decides which variables go into the computer's fast memory (registers) and picks the best machine instructions. It also creates information to help with debugging.
Compiler Correctness
Compiler correctness is about making sure a compiler works exactly as its language rules say it should. This is done by using careful design methods and thorough testing.
Compiled vs. Interpreted Languages
Programming languages are often thought of as either compiled or interpreted. However, a language can often be both. The difference usually comes from how it's most commonly used. For example, BASIC is often called interpreted, and C is called compiled, even though compilers for BASIC and interpreters for C exist.
Interpretation doesn't completely replace compilation. An interpreter itself needs to be run by machine instructions at some point.
Modern trends like just-in-time compilation (JIT) and bytecode interpretation blur the lines even more. A JIT compiler compiles code right when it's needed during the program's run. For example, Java programs are first compiled into a machine-independent bytecode. This bytecode is then run by an interpreter. But if a part of the code is used often, the JIT compiler will turn that part into fast machine code.
Some languages, like Common Lisp, require a compiler. Others, like many scripting languages, are very easy to implement with an interpreter. These languages might let programs create new code while they are running. To do this in a compiled language, the program needs to include a part of the compiler itself.
Types of Compilers
Compilers can be classified by the type of computer or system their code is made for. This is called the target platform.
A native or hosted compiler creates code that runs on the same type of computer and operating system as the compiler itself. A cross compiler creates code for a different platform. Cross compilers are often used for embedded systems, like the small computers in appliances.
Compilers that create code for a virtual machine (VM) are usually not called native or cross compilers. This is because the VM code might run on the same or a different platform.
Sometimes, a compiler's target language is another high-level language. For example, Cfront, the first compiler for C++, turned C++ code into C code. This C code was then compiled into machine code. C is often used as a target language because it's very flexible and works on many different systems.
While most compilers create machine code, there are other types:
- Source-to-source compilers (or transpilers) take a high-level language as input and output another high-level language. They might, for example, add code to make a program run faster on multiple processors.
- Bytecode compilers create code for a theoretical machine. Java and Python compilers are examples of this. Their code runs on a Java Virtual Machine (JVM) or Python Virtual Machine.
- Just-in-time compilers (JIT compilers) compile code while the program is running. They are used in many modern languages like Python, JavaScript, and Java.
- Hardware compilers (or synthesis tools) take a hardware description language as input. They output a design for computer hardware, like a field-programmable gate array (FPGA). These compilers control how the actual electronic circuits will work.
- A decompiler translates code from a low-level language to a higher-level one.
- A binary recompiler rewrites existing machine code to optimize it without changing its type.
Assemblers are programs that turn human-readable assembly language into machine code. They are usually not called compilers. The opposite of an assembler is a disassembler, which turns machine code back into assembly language.
Images for kids
-
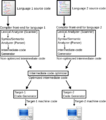
A diagram showing how a typical compiler works. It can handle many languages and create code for different systems.
-

A diagram showing the three main stages of compiler design.
-
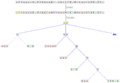
Lexer and parser example for C. Starting from the sequence of characters "
if(net>0.0)total+=net*(1.0+tax/100.0);", the scanner composes a sequence of tokens, and categorizes each of them, for example as identifier, reserved word, number literal, or operator. The latter sequence is transformed by the parser into a syntax tree, which is then treated by the remaining compiler phases. The scanner and parser handles the regular and properly context-free parts of the grammar for C, respectively.

See also
 In Spanish: Compilador para niños
In Spanish: Compilador para niños
- Abstract interpretation
- Bottom-up parsing
- Compile and go system
- Compile farm
- List of compilers
- List of important publications in computer science § Compilers
- Metacompilation
- Program transformation
