
Translation (biology) facts for kids




In biology, translation is a key process inside living cells. It's how cells make proteins using instructions from RNA molecules. Think of RNA as a recipe. The protein made is a chain of tiny building blocks called amino acids. The order of these amino acids is set by the order of nucleotides in the RNA.
These nucleotides are read in groups of three. Each group, called a codon, tells the cell which specific amino acid to add. This matching system from codons to amino acids is known as the genetic code. A special cell machine called a ribosome does all the work of translation. This whole process, from gene to protein, is part of gene expression.
During translation, a type of RNA called messenger RNA (mRNA) is "read" by a ribosome. This happens outside the cell's nucleus. The ribosome then builds a specific chain of amino acids, known as a polypeptide. This polypeptide chain then folds into an active protein. These proteins then do important jobs inside the cell. The ribosome helps by matching parts of the mRNA (codons) with special tRNA molecules. These tRNAs carry the correct amino acids. As the mRNA moves through the ribosome, the amino acids are linked together to form the protein chain.
Contents
How Cells Make Proteins: The Three Steps
Translation happens in three main steps:
- Initiation: The ribosome first gets together around the mRNA molecule. The very first tRNA, carrying the first amino acid, attaches to a special "start" codon on the mRNA.
- Elongation: The ribosome moves along the mRNA. It keeps adding amino acids one by one to the growing protein chain. Each new amino acid is brought by a tRNA. The ribosome links it to the previous amino acid. This process builds the protein chain longer and longer.
- Termination: When the ribosome reaches a "stop" codon on the mRNA, the process ends. The completed protein chain is released. The ribosome then breaks apart or moves on to translate another mRNA molecule.
In simple cells like prokaryotes (bacteria and archaea), translation happens in the main part of the cell, called the cytosol. In more complex cells like eukaryotes, translation can happen in the cytoplasm. It can also happen on the surface of the endoplasmic reticulum, a network inside the cell. When it happens on the endoplasmic reticulum, the new protein can be stored there. It can also be sent out of the cell later.
Not all RNA molecules become proteins. Many types of RNA, like transfer RNA (tRNA) and ribosomal RNA (rRNA), have other important jobs in the cell. They don't get translated into proteins themselves.
Some antibiotics work by stopping translation. They target the ribosomes in bacteria. Since bacterial ribosomes are different from human ribosomes, these medicines can fight infections without harming human cells. Examples include chloramphenicol and tetracycline.
The Ribosome: Protein Factory


Making a protein means adding one amino acid at a time to the end of a growing chain. The ribosome does this job. A ribosome has two parts: a small part and a large part. These two parts come together on the mRNA to start making the protein.
The mRNA molecule acts like a blueprint. It tells the ribosome which amino acid to add next. The mRNA is read in groups of three nucleotides, called codons. Each codon tells the ribosome which specific amino acid to use. This way, the order of nucleotides in the mRNA decides the exact order of amino acids in the protein.
The ribosome is like a factory where amino acids are put together. It contains rRNA and other proteins. tRNA molecules are small RNA chains. They act like delivery trucks, bringing the correct amino acids to the ribosome. Each tRNA has a special spot to hold an amino acid. It also has an "anticodon" part. This anticodon matches up with a codon on the mRNA.
Special enzymes called aminoacyl tRNA synthetases make sure each tRNA gets the correct amino acid. Once a tRNA has its amino acid, it's called "charged."
The ribosome has two main spots for tRNAs: the A-site and the P-site.
- The A-site (aminoacyl site) is where a new tRNA, carrying its amino acid, first arrives and matches its anticodon to the mRNA codon.
- The P-site (peptidyl site) holds the tRNA that has the growing protein chain attached to it.
When a new tRNA arrives at the A-site, the ribosome forms a bond between the new amino acid and the growing protein chain. The protein chain then moves to the tRNA in the A-site. The ribosome then shifts along the mRNA. The tRNA that was in the A-site, now holding the protein chain, moves to the P-site. The empty tRNA from the P-site leaves the ribosome. Then, a new tRNA can enter the A-site, and the process repeats.
Making proteins uses a lot of energy. The ribosome moves along the mRNA, adding amino acids very quickly. In bacteria, it can add up to 21 amino acids per second! In human cells, it's a bit slower, around 6-9 amino acids per second.
Sometimes, mistakes happen during translation. A wrong amino acid might be added, or the process might stop too early. However, cells have ways to keep these errors low.
The process starts when the small part of the ribosome attaches to the beginning of the mRNA. This happens with the help of special proteins called initiation factors. In bacteria, there's a specific sequence on the mRNA called the Shine-Dalgarno sequence. This helps the ribosome know exactly where to start.
Translation stops when the ribosome reaches a "stop codon" on the mRNA. These stop codons (UAA, UAG, or UGA) don't have a matching tRNA. Instead, special proteins called release factors bind there. They tell the ribosome to release the completed protein chain. The ribosome then breaks apart from the mRNA.
Cells carefully control the translation process. This control affects how many proteins are made. It also helps cells respond to changes in their environment.
Scientists use a method called ribosome profiling to study translation. This technique lets them see which parts of mRNA are being translated into proteins at a specific time. It helps them understand how genes are turned into proteins. A newer method, single-cell ribosome profiling, even lets them study this process in individual cells. This is important because even cells of the same type can make proteins differently.
Translation and Health
Controlling translation is very important for diseases like cancer. Cancer cells often change how they make proteins. This helps them grow and survive. Many important cell pathways that go wrong in cancer, like RAS-MAPK and PI3K/AKT/mTOR, end up changing protein production. Cancer cells also use translation control to deal with stress. For example, they might make proteins that help them avoid apoptosis (programmed cell death) when they don't have enough nutrients. Scientists hope that by understanding and targeting translation, they can develop new ways to fight cancer.
Understanding the Genetic Code
You can even figure out a protein's amino acid sequence yourself, especially for short pieces of RNA. This helps scientists understand the chemical structure of the protein.
First, you need to know that DNA and RNA use slightly different letters (bases). DNA has A, T, C, G. RNA has A, U, C, G (U replaces T). When RNA is made from DNA, the bases match up like this:
- DNA A becomes RNA U
- DNA T becomes RNA A
- DNA C becomes RNA G
- DNA G becomes RNA C
Next, you take the RNA sequence and split it into groups of three bases. Remember, you can start reading at different points, which changes the "reading frame" and the protein sequence.
Finally, you use a special table (like the one for the genetic code) to find out which amino acid each three-base group (codon) codes for. This gives you the basic sequence of amino acids in the protein.
This process gives you the protein's primary structure (the amino acid sequence). However, proteins also fold into complex 3D shapes. This folding depends on how the amino acids interact. Predicting the final 3D shape (called tertiary structure) is much harder and requires special computer programs.
Sometimes, unusual amino acids can be added to a protein. For example, selenocysteine is coded for by a "stop" codon, but only if there's a special signal nearby.
Many computer programs can translate DNA or RNA sequences into protein sequences. Most use the standard genetic code. However, some special cases exist, like alternative start codons. For example, the codon CTG usually codes for Leucine, but if it's a start codon, it codes for Methionine.
Here's a simple example of a translation table for the Standard Genetic Code: AAs = FFLLSSSSYY**CC*WLLLLPPPPHHQQRRRRIIIMTTTTNNKKSSRRVVVVAAAADDEE$ Starts = ---M---------------M---------------M---------------------------- Base1 = TTTTTTTTTTTTTTTTCCCCCCCCCCCCCCCCAAAAAAAAAAAAAAAA$$$$ Base2 = TTTTCCCCAAAA$TTTTCCCCAAAA$TTTTCCCCAAAA$TTTTCCCCAAAA$ Base3 = TCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAG
The "Starts" row shows common start codons like AUG. When these are start codons, they all lead to the amino acid methionine.
Different Translation Tables
Even within the same organism, different parts of the cell might use slightly different genetic codes. For example, the genes in the mitochondria (the cell's powerhouses) often use a different code than the genes in the nucleus. The NCBI lists many different translation tables, including:
- The standard code
- The vertebrate mitochondrial code
- The yeast mitochondrial code
- The bacterial, archaeal and plant plastid code
- And many others for specific organisms or cell parts.
More to Explore
- Cell (biology)
- Cell division
- DNA codon table
- Gene expression
- Gene
- Genome
- Protein methods
- Start codon
Images for kids
-
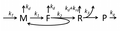
Figure M0. A basic model of how proteins are made.
-
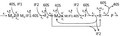
Figure M1'. A more detailed model of protein synthesis, showing how different parts join.
See also
 In Spanish: Traducción (genética) para niños
In Spanish: Traducción (genética) para niños
