
Btrfs facts for kids
| Developer(s) | SUSE, Meta, Western Digital, Oracle Corporation, Fujitsu, Fusion-io, Intel, The Linux Foundation, Red Hat, and Strato AG |
|---|---|
| Full name | B-tree file system |
| Introduced | March 23, 2009 with Linux kernel 2.6.29 |
| Partition IDs |
|
| Structures | |
| Directory contents | B-tree |
| File allocation | Extents |
| Bad blocks | None recorded |
| Limits | |
| Max volume size | 16 EiB |
| Max file size | 16 EiB |
| Max no. of files | 264 |
| Max filename length | 255 ASCII characters (fewer for multibyte character encodings such as Unicode) |
| Allowed filename characters |
All except '/' and NUL ('\0') |
| Features | |
| Dates recorded | Creation (otime), modification (mtime), attribute modification (ctime), and access (atime) |
| Date range | 64-bit signed int offset from 1970-01-01T00:00:00Z |
| Date resolution | Nanosecond |
| Attributes | POSIX and extended attributes |
| File system permissions |
Unix permissions, POSIX ACLs |
| Transparent compression |
Yes (zlib, LZO and (since 4.14) ZSTD) |
| Transparent encryption |
Planned |
| Data deduplication | Yes |
| Copy-on-write | Yes |
| Other | |
| Supported operating systems |
Linux, Windows, ReactOS |
Btrfs (pronounced "better F S" or "butter F S") is a special way computers organize and store information. Think of it like a super-smart filing cabinet for your digital files. It uses a method called "copy-on-write" (CoW). This means when you change a file, Btrfs doesn't just overwrite the old data. Instead, it makes a new copy of the changed parts. This helps keep your data safe and allows for cool features like snapshots.
Btrfs was created by Chris Mason in 2007 for computers running Linux. It was designed to help Linux handle very large amounts of storage. It also makes it easier to manage files and keep them reliable. Btrfs helps with things like making copies of your entire system (snapshots) and checking if your files are still in good condition.
Contents
How Btrfs Was Developed

The Idea Behind Btrfs
The main idea for Btrfs came from an IBM researcher named Ohad Rodeh in 2007. He suggested using a special type of data structure called a B-tree. This structure helps organize data efficiently. Chris Mason, who was working on other file systems, started building Btrfs based on this idea.
Why Btrfs Was Needed
Older file systems, like ext4, were good but not designed for the huge amounts of data we use today. Experts like Theodore Ts'o said that Btrfs was a better way forward. It offered improvements in how much data it could handle. It also made managing files easier and more reliable.
Becoming Part of Linux
Btrfs was officially added to the Linux kernel in 2009. The Linux kernel is the core part of the Linux operating system. This meant that many Linux computers could start using Btrfs. Some Linux versions even offered it as an experimental option when you installed them.
Growing and Improving
Over the years, Btrfs kept getting better. In 2011, features like automatic defragmentation and data checking were added. Many developers from different companies helped improve Btrfs. Chris Mason, the main creator, continued his work on it even when he moved to new companies.
Btrfs in Different Linux Versions
By 2012, some Linux versions, like Oracle Linux and SUSE Linux Enterprise, started supporting Btrfs for everyday use. In 2015, SUSE Linux Enterprise Server (SLE) made Btrfs its default file system. This showed that Btrfs was becoming a trusted choice.
However, not all Linux versions kept Btrfs as a main feature. Red Hat Enterprise Linux (RHEL) removed it in 2019. But in 2020, Fedora Linux chose Btrfs as the default for its desktop versions. This shows that Btrfs is still an important and evolving file system.
Key Features of Btrfs
Btrfs has many cool features that make it powerful and reliable. These features help protect your data and make managing files easier.
Self-Healing and Data Protection
- Self-healing: Btrfs can often fix itself if it finds small errors. This is thanks to its copy-on-write design.
- Online data scrubbing: This feature scans your file system in the background. It looks for errors and automatically fixes them if you have extra copies of your data.
- Checksums: Btrfs creates special codes (checksums) for your data and file information. If a checksum doesn't match, it means the data might be corrupted. Btrfs then tries to get a good copy from another location if available.
Managing Storage Space
- Online defragmentation: This helps keep your files organized on the disk. It makes your computer run faster.
- Volume growth and shrinking: You can easily make your Btrfs storage bigger or smaller while it's still being used.
- Adding and removing devices: You can add or remove storage drives (like hard drives) to your Btrfs system while it's running.
- Balancing: Btrfs can move data around different drives to make sure they are used evenly.
- RAID support: Btrfs supports different RAID levels (like RAID 0, RAID 1, RAID 10). These help combine multiple drives for speed or safety.
Smart File Handling
- Subvolumes: Think of these as separate folders that can be managed like mini-file systems. You can mount them separately.
- Snapshots: These are like instant photos of your subvolumes. They are created very quickly and don't take up much space at first. You can use them to go back to an earlier version of your files.
- File cloning (reflink): This lets you make a copy of a file instantly. The copy doesn't take up extra space until you change it. This is great for saving disk space.
- Compression: Btrfs can automatically compress your files. This saves space on your disk. It uses different compression methods like zlib, LZO, and ZSTD.
Converting and Recovering Data
- In-place conversion: You can change an existing ext2/3/4 or ReiserFS file system to Btrfs without losing your data. You can even undo the conversion if needed.
- Send/receive: This feature lets you create a "diff" (a list of changes) between two snapshots. You can then send these changes to another Btrfs system. This is useful for backups and copying data.
- Recovery tools: If your Btrfs file system has problems, there are tools like
btrfs-restorethat can help you get your files back without damaging the broken system.
Understanding Snapshots and Subvolumes


What are Subvolumes?
A Btrfs subvolume is like a special folder that acts as its own file system. You can set it up to be mounted (connected) separately. This means you can have different parts of your storage organized in a very flexible way. Subvolumes can even be inside other subvolumes.
Every Btrfs file system always has a main subvolume. This is the one that gets mounted by default. You can change which subvolume is the default if you want.
How Snapshots Work
A Btrfs snapshot is a copy of a subvolume at a specific moment in time. Because Btrfs uses "copy-on-write," creating a snapshot is very fast. It doesn't copy all the data right away. Instead, it just notes where the data is. If you change a file in the snapshot, only the changed parts are saved as new data. The original subvolume remains untouched.
Snapshots are great for backups. If something goes wrong with your main files, you can easily switch back to an earlier snapshot. This helps protect your work and system.
How Btrfs is Designed
Btrfs is built using several layers of those special B-trees. These trees help organize all the information on your disk. This includes file data, file names, and even how space is used. Because everything uses the same B-tree system, features like copy-on-write and checksums work for the entire file system.
Storing File Data (Extents)
File data in Btrfs is stored in "extents." These are continuous blocks of data on the disk. When you make a snapshot or clone a file, they share these extents. If you change a small part of a file, Btrfs only copies the changed part. This saves a lot of disk space.
Keeping Track of Space (Extent Allocation Tree)
Btrfs has a special tree called the "extent allocation tree." This tree keeps track of all the free and used space on your disk. It helps Btrfs find the best places to store new data. This design also allows Btrfs to easily shrink, move, or defragment its storage while it's running.
Checking Data Integrity (Checksum Tree)
Btrfs uses a "checksum tree" to store checksums for all your data and file information. A checksum is like a digital fingerprint. If Btrfs reads a block of data and its checksum doesn't match, it knows there's an error. If you have copies of your data (like with RAID), Btrfs can often fix the error automatically.
The Superblock
The "superblock" is a very important part of Btrfs. It stores key information needed to start up the file system. This includes where to find the main trees. Copies of the superblock are kept in several fixed places on your disk. This way, if one copy gets damaged, Btrfs can use another one to start up.
Where Btrfs is Used Today
Btrfs is supported and used in several operating systems and devices:
- Oracle Linux (from version 7)
- SUSE Linux Enterprise Server (from version 12)
- Synology DiskStation Manager (DSM) (from version 6.0)
- Fedora Workstation (from version 33)
It was also included as a "technology preview" in Red Hat Enterprise Linux 6 and 7, but it was later removed in RHEL 8.
Images for kids
-
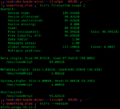
Screenshot of usage information of a Btrfs file system
-
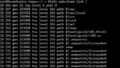
Example of listing of subvolumes of a Btrfs file system, including snapshots
-

Example of snapshots of a Btrfs file system, managed with snapper
-

Example of Btrfs quota groups

See also
 In Spanish: Btrfs para niños
In Spanish: Btrfs para niños
