
RAID facts for kids
RAID is a special way to use several hard disks together in a computer. It stands for Redundant Array of Inexpensive Disks or Redundant Array of Independent Disks. Imagine taking a few separate hard drives and making them work like one big, smart drive. This helps computers store and access information better.
People use RAID for a few main reasons:
- To keep your data safe from being lost. This is done by making extra copies of your important files.
- To get more storage space by combining many smaller disks into one larger one.
- To make the system more flexible. You can sometimes change or add disks without stopping the computer.
- To get your data much faster.
It's hard to get all these benefits at once, so choices need to be made.
There are also some things RAID can't do:
- Some RAID setups protect against a disk breaking. But they don't protect against you accidentally deleting or changing your data.
- If a disk breaks and you replace it, the system needs time to rebuild the data. This can take a long time, especially with very large disks.
- Some rare errors can still make it impossible to read your data.
Most of the ideas for RAID came from a special paper written in 1988.
Companies have used RAID for a long time to store their data. Now, it's cheaper to build RAID systems. So, even some home computers and devices use RAID. For example, you might find it in systems that store lots of music or movies.
Understanding How Disks Work
Physical Disks vs. Logical Disks
A hard disk is a physical part of your computer. It stores information using magnetism. When you use a computer, the operating system sees these hard disks. For example, in Microsoft Windows, each hard disk usually gets a letter like C: or D:. In Linux systems, it's a bit different, but the idea is similar.
We call the actual hard drives you can touch physical drives. What your operating system shows you is called a logical disk. A physical drive can be split into smaller parts called partitions. Each partition acts like its own logical disk.
So, to you, a "logical disk" might be a whole physical drive, or just a part of one. You often can't tell the difference just by looking at it on your screen.
How Computers Read and Write Data
Inside a computer, all information is stored as tiny pieces called bits and bytes. Usually, 8 bits make up one byte. Computer memory uses electricity to store data. Hard disks use magnetism.
When you write data to a disk, the computer changes electrical signals into magnetic ones. When you read data from a disk, the computer turns the magnetic signals back into electrical ones.
What is a RAID Array?
A RAID array connects two or more hard disks to make them act like one big logical disk. This is done for several reasons:
- To prevent data loss if one or more disks in the array break.
- To make data transfers faster.
- To allow you to change disks while the computer is still running.
- To combine many cheaper disks to get more storage space than one expensive disk.
RAID uses special hardware or software inside your computer. The connected hard disks then look like a single hard disk to you. Most RAID setups add redundancy. This means they store data multiple times or store special information to rebuild data. This way, if some disks fail, your data is still safe. When a broken disk is replaced, the system copies or rebuilds the missing data from the other disks. This rebuilding can take a long time, depending on how big the system is.
Why Use RAID?
Many companies use RAID because it helps keep their data available. People using the data don't even need to know it's running on RAID. If a disk fails and the system is rebuilding, access to data might be slower. But it's still much better than not being able to use the data at all!
However, depending on the RAID setup, if another disk fails while the system is rebuilding, you could lose all your data.
The different ways to combine disks are called RAID levels. A higher number doesn't always mean it's better. Different RAID levels are for different purposes. Some need special disks or controllers.


The History of RAID
In 1978, a person named Norman Ken Ouchi at IBM suggested ideas that were similar to what we now call RAID.
Later, in 1987, researchers at the University of California, Berkeley worked on making RAID technology use more than one hard drive. They found that using two drives gave much more storage. But it also caused more crashes.
In 1988, David Patterson, Garth Gibson, and Randy Katz wrote an important article. It was called "A Case for Redundant Arrays of Inexpensive Disks (RAID)". This article first used the name RAID, and it became the official term.
Core Ideas Behind RAID Systems
RAID uses a few main ideas to work. These were explained in a paper by Peter Chen and others in 1994.
Caching: Making Things Faster
Caching is a trick used to speed up computers, and it's also used in RAID systems. A cache is like a temporary storage area that holds data the computer might need soon.
When you tell the computer to write data, it often first writes it to the cache. The computer then tells you it's done, even if the data hasn't reached the actual disk yet. This can make things faster. However, if the computer suddenly loses power, some data might not have been fully written to the disk. To prevent this, many systems have a cache that has its own battery backup.
Mirroring: Having Copies of Data
Mirroring is a simple idea. Instead of having your data in just one place, you have several copies. These copies are usually on different hard disks. If you have two copies, and one disk breaks, your data is still safe on the other copy.
Mirroring can also make reading data faster because the system can read from the quickest disk. However, writing data is slower because all copies need to be updated.
Striping: Spreading Data Across Disks
With striping, data is split into small parts. These parts are then saved on different disks. This makes writing data much faster because the disks can work at the same time. But if one disk fails, you lose part of the data, so this method doesn't protect against faults on its own.
Error Correction and Faults
Computers can calculate special codes called checksums. Some checksums can only tell you if there's a mistake. Most RAID levels that use extra copies of data can do this. Other, more complex methods can not only find an error but also fix it.
Hot Spares: Extra Disks Ready to Go
Many RAID systems use something called a hot spare. This is an empty disk that isn't used normally. If a disk in the RAID system fails, the data can be copied directly onto the hot spare disk. Then, you just replace the broken disk with a new empty one, and it becomes the new hot spare.
Stripe Size and Chunk Size: How Data is Spread
RAID spreads data across several disks. Two important terms for this are stripe size and chunk size.
The chunk size is the smallest piece of data written to a single disk in the array. The stripe size is the total size of a block of data that will be spread across all disks. For example, with four disks and a stripe size of 64 kilobytes (kB), each disk gets 16 kB. So, the chunk size is 16 kB. A bigger stripe size can mean faster data transfer but also a longer time to get a single block of data.
Combining Disks: JBOD
Many systems can combine disks in a simple way: they fill up the first disk, then move to the second, and so on. This makes several smaller disks look like one big one. This is called just a bunch of disks (JBOD).
JBOD is not true RAID because it doesn't have any extra copies of data for safety. If one disk fails, you lose the data on it. But it's useful for combining disks of different sizes into one larger storage space. For example, you could combine a 3 GB, 15 GB, and 5.5 GB drive into one 23.5 GB logical drive.

Drive Clone: Replacing Disks Early
Most modern hard disks have a feature called Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T). SMART helps monitor the health of a hard disk. Some RAID systems can replace a disk even before it completely fails. For example, if SMART reports too many small errors, the system can copy all data to a hot spare. Then, you can replace the old disk.
Different RAID Setups
The way disks are set up and how they use these techniques affects how well the system performs and how reliable it is. When you use more disks, there's a higher chance one of them might fail. Because of this, RAID systems need ways to find and fix errors. This makes the whole system more reliable, as it can survive and repair disk failures.
Common RAID Levels Explained
RAID Levels You'll Often See
RAID 0: Speeding Things Up with Striping
RAID 0 isn't truly "RAID" because it doesn't have any redundancy (extra copies for safety). With RAID 0, disks are simply combined to make one large, fast disk. This is called "striping." Data is split and written across all disks at the same time. This makes reading and writing data much faster.
However, if just one disk in a RAID 0 setup fails, you lose all the data on the entire array. Because of this, RAID 0 is rarely used for very important data. All disks used in RAID 0 should be about the same size.
RAID 0 is sometimes used for temporary storage areas, like swap space on Linux computers.
RAID 1: Mirroring for Safety
With RAID 1, two disks are used together. Both disks hold exactly the same data. One disk is a "mirror" of the other. This setup is simple and fast to use, whether it's done with special hardware or software.
If one disk fails, the other disk still has all your data, so nothing is lost.
RAID 5: Balancing Speed and Safety
RAID Level 5 is one of the most common types of RAID. You need at least three hard disks for a RAID 5 system. In RAID 5, data is spread across all disks, similar to RAID 0. But it also calculates special checksums (called "parity") for the data. These checksums are also spread across all disks.
This means that if one disk fails, the system can use the data and the checksums from the other disks to rebuild the missing information. This makes it very safe against a single disk failure. The total usable space will be the size of all disks minus one (because one disk's worth of space is used for the checksums).
Writing data to RAID 5 is a bit slower than RAID 0 or 1 because the system needs to calculate and update the checksums. But reading data is almost as fast as RAID 0.
If a disk fails, a RAID 5 system will keep working, but it will be slower. This is called "degraded mode." To help with this, an extra disk called a hot spare is often added. If a disk fails, the data can be rebuilt directly onto the hot spare.
RAID 5 Pictures
-
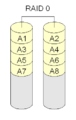
RAID 0 simply puts different blocks of data on different disks. There are no extra copies for safety.
-
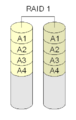
With RAID 1, every block of data is on both disks, creating a mirror.
-
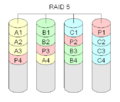
RAID 5 calculates special checksums for the data. Both the data and the checksums are spread over all disks.



Less Common RAID Levels
RAID 2: For Very Large Computers
RAID 2 was used with very large, powerful computers. It needed special, expensive disks and controllers. Data was split into tiny pieces (bits). It used complex calculations called Hamming codes to find and fix errors. RAID 2 is the only RAID level that can actually repair errors, not just detect them.
RAID 2 needed at least 10 disks. Because it was so complex and expensive, it's not used much anymore.
RAID 3: Striping with a Dedicated Parity Disk
RAID Level 3 is similar to RAID Level 0. It adds an extra disk just to store the checksum (parity) information. This parity disk holds the checksums for all the data on the other disks.
The problem with this is that if the single parity disk breaks, you lose the safety feature. RAID 3 usually needs at least 3 disks.
RAID 4: Similar to RAID 3, but Better
RAID 4 is very similar to RAID 3. The main difference is that it calculates parity over larger blocks of data, not single bytes. This is more like RAID 5. You need at least three disks for a RAID 4 system.
RAID 6: Extra Safety for Two Disk Failures
RAID level 6 is an improved version of RAID 5. It adds a second checksum (parity block) to the array. This means it needs at least four disks (two for data, two for safety). With RAID 6, your system can keep working even if two disks fail at the same time.
RAID 6 is slower than RAID 5 when writing data because it has to calculate two different checksums. But it's becoming popular because it offers much better protection against data loss, especially when rebuilding a large array.
RAID 6 Pictures
-
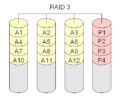
RAID 3 is like RAID 0, but with an extra disk to hold checksums for each block of data.
-
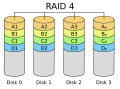
RAID 4 is similar to RAID 3, but it calculates checksums over larger blocks of data.
-
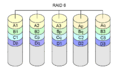
RAID 6 is like RAID 5, but it calculates two different checksums. This lets two disks fail without losing data.



Special RAID Levels
Double Parity / Diagonal Parity
This is another way to have two checksums, similar to RAID 6. It uses different calculations for each checksum. The industry now considers this a form of RAID 6.
RAID 1.5
RAID 1.5 is a special type of RAID made by one company. It uses only two disks, like RAID 1, but it combines both striping (like RAID 0) and mirroring (like RAID 1). Most of its work is done by special hardware.
RAID 5E, RAID 5EE and RAID 6E
These are enhanced versions of RAID 5 or RAID 6. The "E" stands for "Enhanced." They include a "hot spare" disk, but it's not a separate physical disk. Instead, it's free space spread across the existing disks. This can make performance better, but it means that hot spare space can't be shared between different RAID systems.
RAID Z
ZFS is a special file system designed for huge amounts of data. It has a feature called RAID-Z. It avoids a problem called the "write hole" (where data might get corrupted if power goes out during a write). RAID-Z doesn't overwrite data directly. Instead, it writes new data to a new spot on the disk. Once the write is successful, the old data is removed. There's also RAID-Z2, which uses two forms of checksums, like RAID 6, to protect against two disk failures.
Special RAID Pictures
-

A diagram of a RAID DP (Double Parity) setup.
-
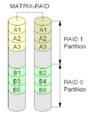
An example of an Intel Matrix RAID setup.


Combining RAID Levels
You can also combine different RAID levels to get even more benefits. This is like building a RAID system out of other RAID systems. People often write this by putting the numbers together, like RAID 0+1 or RAID 1+0.
Here are some common combinations:
- RAID 0+1: This combines two or more RAID 0 arrays (which are fast but not safe) into a RAID 1 array (which mirrors for safety). It's like having a "mirror of stripes."
- RAID 1+0: This is the opposite of RAID 0+1. It takes several RAID 1 arrays (mirrors) and combines them into a RAID 0 array (striping). This is called a "stripe of mirrors." It's generally safer than RAID 0+1.
- RAID 5+0: This stripes several RAID 5 arrays together using RAID 0. One disk in each RAID 5 array can fail, but if a second disk in the same RAID 5 array fails, you lose all data for that part.
- RAID 6+0: This stripes several RAID 6 arrays together using RAID 0. Two disks in each RAID 6 array can fail without losing data.
For example, with six 300 GB disks (1.8 TB total):
- A single RAID 5 gives you 1.5 TB of usable space, and one disk can fail.
- RAID 50 might give you 1.2 TB, but one disk from each RAID 5 part can fail, and it's faster.
- RAID 51 might give you 900 GB, but any three drives can fail without data loss.
-
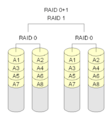
RAID 0+1: Several RAID 0 arrays are combined with a RAID 1.
-
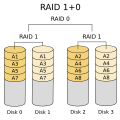
RAID 1+0: Stronger than RAID 0+1. It can handle multiple drive failures, as long as no two drives in the same mirror fail.
-
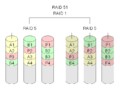
RAID 5+1: Any three drives in this setup can fail without losing data.



How to Make a RAID System
You can set up RAID in a few ways: using software or special hardware.
Software RAID
With Software RAID, your computer's main processor (the CPU) does all the work to manage the RAID. The disks are connected like normal hard drives. This means the CPU has to do calculations for RAID, which can be a lot of work for complex RAID levels like RAID 5 or 6.
A downside is that if your computer breaks, it might be hard to get your data from a Software RAID using a different computer or operating system. Software RAID usually uses parts of hard disks (partitions) rather than whole disks.
Hardware RAID
Hardware RAID uses a special disk controller card. This card has its own microchip that does all the RAID calculations. This means your computer's main CPU doesn't have to do the work. The operating system just sees one big disk, not a RAID array.
Hardware RAID is independent of the operating system. However, different manufacturers make their RAID controllers in different ways. So, a RAID system built with one brand of controller might not work with another brand. Hardware RAID controllers can also be expensive.
Hardware-Assisted RAID
This is a mix of hardware and software RAID. It uses a special chip on the motherboard (like hardware RAID), but this chip can't do all the work. It mostly helps when the system starts up. Once the operating system is fully loaded, it acts more like Software RAID. Many motherboards have these "hardware-assisted RAID" functions. You often need special software to use them and to fix a failed disk.
Terms About Hardware Problems
When talking about hardware breaking, you might hear these terms:
Failure Rate
The failure rate tells you how often a system breaks. RAID systems can't stop individual hard drives from failing. But more complex RAID types can help keep your data safe even if a drive fails.
Mean Time to Data Loss
The mean time to data loss (MTTDL) is the average time before you actually lose data in a RAID system. Depending on the RAID type, this time can be longer or shorter than for single hard disks.
Mean Time to Recovery
RAID systems that have extra copies of data can recover from some failures. The mean time to recovery shows how long it takes for a broken RAID system to get back to normal. This includes the time to replace a broken disk and the time to rebuild the data.
Things to Know About RAID
There are some important things to understand about RAID:
Adding Disks Later
Some RAID levels let you add more hard disks later to make the storage bigger. But adding a disk often means the system has to reorganize all the data, which can take a very long time. It's like rebuilding the entire system. Also, the extra space might not be available right away because the file system needs to be updated. Some file systems can't be made bigger after they are created. In that case, you'd have to back up all your data, rebuild the RAID, and then put your data back.
Linked Failures
RAID assumes that disks fail one by one, independently. But in real life, disks often come from the same batch and are used in similar ways. This means they might wear out at similar times. So, there's a chance that a second disk could fail before you've fixed the first one. This can lead to data loss.
Data Not Fully Written (Atomicity)
When a computer writes data, it expects the whole process to either finish completely or not happen at all. This is called Atomicity.
In RAID systems, new data is usually written over the old data. If something goes wrong during this process (like a power cut), the copies of your data might end up in a mixed-up state. This is a problem known as the "write hole."
Using a battery-backed cache can help with power failures. But not all RAID controllers support this. Many operating systems have features like journaling file systems (like NTFS) to protect against data loss during interrupted writes.
Unreadable Data
Sometimes, small parts of a hard disk can become unreadable due to errors. Modern disks can usually fix these small errors. But if a RAID system is rebuilding after a disk failure, and it hits one of these unreadable spots, it might not be able to rebuild the data. RAID 6 tries to help with this, but it can make writing data very slow.
Write Cache Reliability
A disk system can say a write is done as soon as the data is in its temporary storage (cache), even if it hasn't reached the physical disk yet. If the power goes out, any data still in the cache could be lost.
Hardware RAID controllers often use a battery to protect this cache. If the power fails, the controller can finish writing the data when power returns. However, batteries can wear out, or the power might be off for too long.
Equipment Compatibility
RAID systems built with one type of controller might not work with another. This means if your RAID controller breaks, you might need to find an identical one to get your data back. Or, you'll need a backup. This can be tricky, especially with RAID features built into motherboards.
What RAID Can and Cannot Do
Here's a simple guide to what RAID is good for and what it's not:
What RAID Can Do Well
- RAID can help your system stay online. RAID levels like 1, 0+1/10, 5, and 6 can protect you from a hard disk breaking. Even if a disk fails, your data is still available. Instead of taking a long time to restore data from a tape or DVD backup, RAID lets you rebuild the data onto a new disk from the other disks in the system. While rebuilding, you can still use your data, though it might be slower. This is super important for businesses, as downtime means lost money. For home users, it keeps large media libraries available.
- RAID can make certain tasks faster. RAID levels 0, 5, and 6 use striping. This means multiple spindles (the spinning parts of a hard drive) work together to increase how fast data can be transferred, especially for large files. Programs that work with video or audio files benefit a lot from this. RAID 1 and other striping-based RAID levels can also speed up access for many small, random data requests, like those in a multi-user database.
What RAID Cannot Do
- RAID cannot protect your data from everything. A RAID system usually has one file system. If something goes wrong with that file system, RAID won't help. RAID won't stop a computer virus from destroying data. It won't prevent data from getting corrupted. It won't save data if you accidentally delete or change it. RAID only protects against physical disk failure, not other hardware failures. It also doesn't protect against natural disasters like fires or floods. To truly protect your data, you must make backups to removable media (like DVDs, tapes, or external hard disks) and keep them in a different place. RAID alone won't prevent data loss in a disaster.
- RAID does not make disaster recovery easier. With a single disk, it's usually easy to move it to a new computer. But RAID controllers often need special drivers. Recovery tools that work with single disks might not be able to access data on a RAID array without these special drivers.
- RAID doesn't speed up all applications. This is especially true for typical desktop computer users and gamers. For most desktop programs and games, how fast the disk can find data (seek performance) is more important than how fast it can transfer large files. RAID 0 increases transfer speed, not seek speed. So, RAID 0 often shows little to no speed gain for most desktop applications and games. For users who want the best performance, buying one faster, bigger, and more expensive single disk is often better than using two slower drives in RAID 0. Even with the best drives, RAID 0 might only boost performance by about 10% and could even slow down some games.
- It's hard to move RAID to a new system. With a single disk, you can usually just plug it into a new computer. But with a RAID array, it's not that simple. RAID controllers store special information about how the RAID is set up. If you move the disks to a different controller (even from the same company, but a different model), it might not be able to read that information. So, when moving a RAID array, you usually need to move the controller too. This is very difficult if the RAID functions are built into your computer's motherboard.
Example of RAID Levels
Let's look at a setup with three identical 1 TB disks. Imagine there's a 1% chance of a drive failing in a certain time.
| RAID Level | Usable storage space | Chance of failure
(in percent) |
Chance of failure
(1 in ... cases fail) |
|---|---|---|---|
| 0 | 3 TB | 2.9701% | 34 |
| 1 | 1 TB | 0.0001% | 1 million |
| 5 | 2 TB | 0.0298% | 3356 |
Images for kids
-

Storage servers with 24 hard disk drives each and built-in hardware RAID controllers supporting various RAID levels.
-

A SATA 3.0 controller that provides RAID functions through special software and drivers.
.JPG)

See also
 In Spanish: RAID para niños
In Spanish: RAID para niños
